
目次
1.サンプルデータ
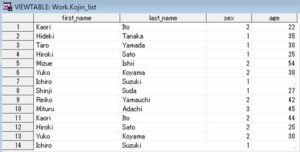
今回は以下のSASデータで重複チェックをしてみます。
data kojin_list;
infile datalines dlm="," dsd missover;
input
first_name :$20.
last_name :$20.
sex
age
;
datalines;
Kaori,Ito,2,22
Hideki,Tanaka,1,35
Taro,Yamada,1,30
Hiroki,Sato,1,25
Mizue,Ishii,2,54
Yuko,Koyama,2,30
Ichiro,Suzuki,1,.
Shinji,Suda,1,27
Reiko,Yamauchi,2,42
Mituru,Adachi,3,45
Kaori,Ito,2,44
Hiroki,Sato,2,25
Yuko,Koyama,2,30
Ichiro,Suzuki,1,.
;
run;
2.展開例
以下は、引数keyとoutdataを省略せずに指定した展開例になります。
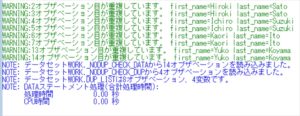
%nodup_check(indata=kojin_list, key=first_name last_name, outdata=dup_list);
重複データが存在する場合、ログにWARNINGが出力されるようになっていますが、重複データが多すぎるとログが長くなるので、重複数が10に達したらログへの出力を停止するようにしています。
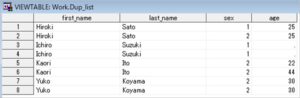
引数outdataを指定した場合は、重複レコードのみのSASデータセットが作成されます。
3.参考プログラム
以下は、参考プログラムになります。
右上のコピーボタンを押せば、プログラム全体をコピーできます。
%macro nodup_check(indata=, key=_all_, outdata=);
%put --------------------------------------------------;
%put nodup_check; /*重複チェックと重複データの抽出*/
%put &=indata; /*チェック対象データセットを指定(データセットオプションの指定可)*/
%put &=key; /*チェック対象KEYを指定(既定値=_all_、全変数)*/
%put &=outdata; /*重複しているレコードのみ出力(省略可)*/
%put --------------------------------------------------;
/*データの読み込み*/
proc sort data=&indata. out=_nodup_check_data;
by &key.;
run;
%if &sysnobs. = 0 %then %put WARNING:入力データセットは空です。;
/*重複データの出力*/
proc sort data=_nodup_check_data(keep=&key.)
out=_nodup_check_nodup
dupout=_nodup_check_dup
nodupkey;
by &key.;
run;
/*重複データの重複削除*/
proc sort data=_nodup_check_dup nodupkey;
by &key.;
run;
/*_nodup_check_dupのOBS数により条件分岐*/
%if &sysnobs. > 0 %then %do;
data
%if %length(%superq(outdata)) > 0 %then %do;
%superq(outdata)
%end;
%else %do;
_null_
%end;
;
merge
_nodup_check_data(in=in1)
_nodup_check_dup(in=in2)
;
by &key.;
if in1 and in2;
_nodup_cnt + 1;
if _nodup_cnt <= 10 then put "WARNING:" _n_ +(-1) "オブザベーション目が重複しています。" +1 (&key.)(=);
if _nodup_cnt = 10 then put "WARNING:重複数が10に達したので、ログへの出力を止めます。";
run;
%end;
%else %put NOTE:重複データは存在しません。;
/*不要データの削除*/
proc datasets lib=work noprint;
delete _nodup_check_:;
quit;
%mend nodup_check;
・20220419 修正
重複データ「_nodup_check_dup 」の重複削除を追加しました。