
目次
構文
PROC SORT DATA = 入力データセット OUT = 出力データセット DUPOUT = 重複データセット NODUPKEY (重複削除オプション) ; BY BY変数(ソートキー); KEY KEY変数(ソートキー); RUN; ※使用頻度の高いステートメントやオプションのみ記載
・DUPOUT=オプションはNODUPKEYを指定したときのみ指定できる
・BYステートメントとKEYステートメントは併用できない
サンプルデータ
サンプルとして、以下のデータを使用していきます。
data sample;
infile datalines dlm="," dsd missover;
input
type :8.
type_name :$200.
type_label :$200.
rank :8.
maker :$200.
model :$200.
uriage :8.
;
datalines;
2,Light,軽自動車,9,ダイハツ,タフト,32191
1,Passenger,乗用車,2,トヨタ,ルーミー,77492
1,Passenger,乗用車,4,トヨタ,カローラ,53864
2,Light,軽自動車,8,ダイハツ,ミラ,36159
1,Passenger,乗用車,7,日産,ノート,46879
1,Passenger,乗用車,5,トヨタ,ハリアー,48271
1,Passenger,乗用車,6,トヨタ,ライズ,47965
2,Light,軽自動車,7,スズキ,アルト,36359
1,Passenger,乗用車,8,トヨタ,ヴォクシー,41101
2,Light,軽自動車,10,日産,デイズ,31558
1,Passenger,乗用車,9,ホンダ,フリード,35551
2,Light,軽自動車,6,スズキ,ハスラー,48221
2,Light,軽自動車,1,ホンダ,N-BOX,110551
2,Light,軽自動車,2,スズキ,スペーシア,78698
1,Passenger,乗用車,1,トヨタ,ヤリス,119112
2,Light,軽自動車,3,ダイハツ,タント,69262
2,Light,軽自動車,4,ダイハツ,ムーヴ,57761
2,Light,軽自動車,5,日産,ルークス,50055
1,Passenger,乗用車,3,トヨタ,アルファード,56778
1,Passenger,乗用車,10,トヨタ,シエンタ,33753
;
run;
使い方
※SAS Studioで実行しているため、BaseSASと出力結果が異なる場合がございます。
昇順ソート
以下はシンプルな昇順ソートの例です。
proc sort data = sample
out = sample_ascending
;
by type rank;
run;
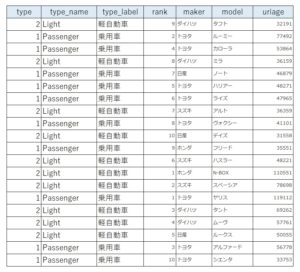
下図の通り、BYステートメントに指定した変数tyepとrankで昇順ソートされています。
ちなみに、上図はOUT=オプションで指定したsample_ascendingの中身になりますが、OUT=オプションを省略し、入力データセットsampleをそのまま上書きすることもできます。
しかし、業務で使用する場合は、基本的に、OUT=オプションの省略は非推奨と考えて良いかと思います。
理由としては、プログラムの規模が大きくなったり、他の人が引き継いだ時に、どの位置でデータセットが更新されたかわからなくなり、ミスが起きたり、デバッグ効率が下がるからです。
DESCENDINGオプションによる降順ソート
以下は、変数typeとrankの前にDESCENDINGオプションを追記して降順ソートする例です。
proc sort data = sample
out = sample_descending
;
by
descending type
descending rank
;
run;
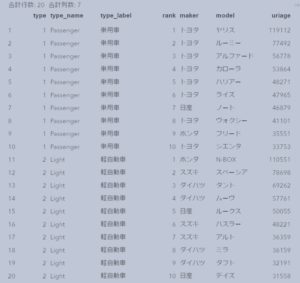
下図の通り、変数typeとrankで降順ソートされています。
KEYステートメントによる降順ソート
以下は、KEYステートメントで昇順ソートと降順ソートを組み合わせた例です。
BYステートメントと異なり、DESCENDINGオプションを変数ごとに記述する必要はなく、「/ DESCENDING」で一括にまとめることができます。
proc sort data = sample
out = sample_descending2
;
key maker;
key type rank / descending;
;
run;
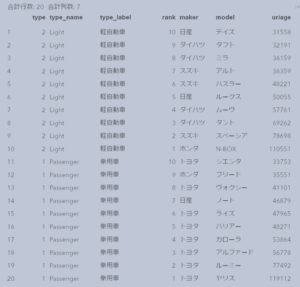
下図の通り、変数makerで昇順ソート後、type、rankの順で降順ソートされています。
NODUPKEYによる重複削除
以下は、各メーカーごとに売上が一番高いレコードのみ抽出する例です。
/*メーカで昇順ソートし、売上で降順ソートする*/
proc sort data = sample
out = sample_uriage
;
by maker descending uriage;
run;
/*重複削除する*/
proc sort data = sample_uriage
out = sample_uriage_nodup
nodupkey
;
by maker;
run;
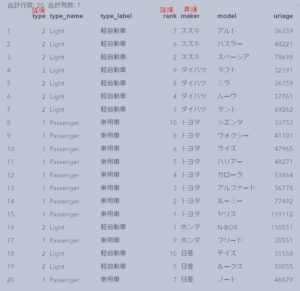
下図の通り、先に売上で降順ソートすることにより、次のPROC SORTのNODUPKEYで、各メーカーの最初に現れるレコードのみ残すことができています。
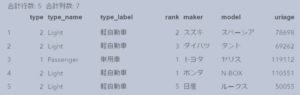
DUPOUT=オプションによる重複データの出力
以下はDUPOUT=オプションで重複データを生成する例です。
/*メーカで昇順ソートし、売上で降順ソートする*/
proc sort data = sample
out = sample_uriage
;
by maker descending uriage;
run;
/*重複削除する*/
proc sort data = sample_uriage
out = sample_uriage_nodup
dupout = sample_uriage_dup
nodupkey
;
by maker;
run;
下図の通り、各メーカーごとに売上が一番高いレコード以外が出力されています。
