
目次
1. 割り当てステートメント(代入文)
DATAステップでは、新たに変数を作成したり、数値を計算してその結果を変数に代入したりすることができる。そうした変数処理の基本となるのが割り当てステートメントである。
data sample_wariate; length shamei name w $200. ; shamei = "39株式会社"; *文字値の代入(文字値を引用符で囲む); name = ""; *文字欠損値の代入(ブランクを引用符で囲む); w = "39" || "株式会社";*連結演算子による連結文字列を代入; price = 39; *数値の代入; total = .; *数値欠損値の代入(半角ピリオドで表す); v = 3 + 9 ; *数値演算の結果を代入; x = price + v ; *右辺にも変数を指定; y = sum(price, v) ; *sas関数を指定; y = y + 1; *右辺に指定した変数の値を変更; run;

①算術演算子
| 優先順位 | 演算子 | 処理 | 使用例 | 結果 |
| 1 | ** | 累乗 | x**y | xのy乗 |
| 2 | * | 乗算 | x*y | xのy倍 |
| 2 | / | 除算 | x/y | xをyで割った値 |
| 3 | + | 加算 | x+y | xにyを加えた値 |
| 3 | - | 減算 | x-y | xからyを引いた値 |
上記のとおり、算術演算子の実行順序には優先順位が設定されている。しかし、カッコを利用することで、任意の優先順位に指定することも可能である。ひとつの演算式内で、同じ優先順位の演算子が重複している場合、基本的には左から右へ順番に実行されるが、累乗のみ右から左へ実行されることに注意が必要である。
x=2**3**4; は、x=2**(3**4); と同じ。
②文字列連結演算子(文字列の連結・結合)
data sample_renketsu; length sei mei name1-name3 $20. ; sei = "山田"; mei = "太郎"; name1 = sei || " " || mei; name2 = trim(sei) || " "|| trim(mei); name3 = catt(sei, " ", mei); run;

name1:長さ20バイトの「sei="山田 "」と長さ20バイトの「mei="太郎 "」を連結しているので、長さ20バイトのname1にはseiの部分しか格納されていない。 name2:TRIM関数で末尾の空白を削除しているので、「name2="山田 太郎"」、と意図した通りに格納されている。 name3:末尾の空白を削除して文字列を連結するCATT関数を使用しているので、「name3="山田 太郎"」、と意図した通りに格納されている。
③SAS関数
SASには、算術演算・統計量算出・文字列処理・日付処理など様々なタスクを実行する関数が用意されている。用途に応じた適切な関数を使用することで効率的なプログラミングが可能となる。
SAS関数の基本形式
関数名(引数1, 引数2, ・・・)
data sample_func; a = 1; b = 2; c = .; total1 = sum(a, b, c); total2 = sum(of a b c); run;

total1:引数をカンマ「,」区切りで指定している。
total2:関数によっては引数をリスト形式「of」で指定することもできる。
④算術演算子とSAS関数(算術・統計関数)における数値欠損値処理の違い
「+」演算子とSUM関数は基本的に同じ結果が得られるが、数値欠損値に対する処理で違いが生じる。
関数名(引数1, 引数2, ・・・)
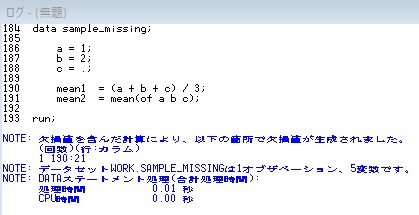
data sample_missing; a = 1; b = 2; c = .; mean1 = (a + b + c) / 3; mean2 = mean(of a b c); run;

mean1:算術演算子の場合、欠損値を含む演算の結果は欠損値となる。
mean2:SAS関数の場合、引数内の欠損値を除外し、有効値のみを使って算出する。
計算式に欠損値が含まれていると、「NOTE: 欠損値を含んだ計算により、以下の箇所で欠損値が生成されました。」のNOTEがログに出力される。
2. 変数の各種制御
DATAステップ内で、ステートメントやデータセットオプションを使用することで、作成するSASデータセットにどの変数を書き込むか制御したり、変数名を変更したりすることができる。
data SASデータセット名(オプション名=値); set SASデータセット名(オプション名=値); SASステートメント ; SASステートメント ; ・・・; run;
①KEEPを使った変数の保持
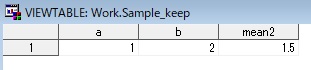
【KEEPステートメントの例】 data sample_keep; keep a b mean2 ; set sample_missing; run;
keepステートメントは、DATAステップの最終過程(すべてのオブザべーションの処理が終わって、SASデータセットを完成させる直前)の段階で作用する。
したがってDATAステップのステートメントであるが、記述位置は問わず、どの位置に記述しても結果は同じになる。これを非実行ステートメントという。
【KEEPデータセットオプションの例】 data sample_keep; set sample_missing(keep=a b mean2); run;
データセットオプションは、作成済みの完成したデータセットに対して作用する。ゆえに、PROCステップでも使用することができる。
上記の例だと、どちらを実行しても下図のSASデータセットが作成される。
しかし、KEEPデータセットオプションで必要な変数のみ保持した方がメモリ消費を防げるので、ビッグデータを読込む際は、どちらを使用するかしっかりと考える必要がある。
②DROPを使った変数の除外
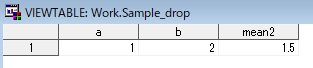
【DROPステートメントの例】 data sample_drop; drop c mean1 ; set sample_missing; run; 【DROPデータセットオプションの例】 data sample_drop; set sample_missing(drop=c mean1); run;
上記の例だと、どちらを実行しても下図のSASデータセットが作成される。
※KEEPとDROPの使い分け
KEEPとDROPは、指定する変数群を逆にすれば同じ結果を得ることができる。基本的にはKEEPを使用することを推奨している。その理由は、作成するデータセットに含まれる変数が明示されることになるので、プログラムやデータ構造の見通しが良くなり、保守性が高まるからである。
しかし、保持する変数が多数、言い換えると、除外する変数が少数の場合は、DROPを使用することもあるので、両者をどう使い分けるかについてはケースバイケースと言える。
③RENAMEを使った変数名の変更
【RENAMEステートメントの例】 data sample_rename; rename c = c_miss mean1= mean1_miss ; set sample_missing; run; 【RENAMEデータセットオプションの例】 data sample_rename; set sample_missing(rename=(c=c_miss mean1=mean1_miss)); run;
上記の例だと、どちらを実行しても下図のSASデータセットが作成される。

④実行ステートメントと非実行ステートメント
「01_SASプログラミングの基本」でDATAステップ内のステートメントは、記述された順番に処理されると説明した。つまり、直前で加工した変数を使って、次のステートメントでさらに別の処理を追加する場合、目的通りの流れに沿ってステートメントを記述しなければ、望んだ結果が得られないことになる。
こうした、オブザべーションのデータを直接、編集・操作するステートメントを「実行ステートメント」と呼ぶ。つまり、実行ステートメントについては、その記述順を意識する必要があるということである。例えば、割り当てステートメントは典型的な実行ステートメントである。
一方、ここで説明したKEEP、DROP、RENAMEの各ステートメントは、位置は問わず、どこに記述しても結果は同じになる。オブザべーションのデータを直接操作するのではなく、DATAステップの最終過程で作用するだけのステートメントだからである。こうした、データを直接操作しないステートメントのことを「非実行ステートメント」(宣言ステートメント)と呼ぶ。これらのステートメントは、作成したデータセットの構造を明示する側面があので、プログラム・データ構造の明瞭さ・わかりやすさという観点から、DATAステップの開始近くに記述することを推奨している。
3. SAS変数リスト
SASでは、ステートメントや関数の引数として、変数名を列挙する際に、各種略記法を使用することができる。
①数字付き範囲リスト
最後の文字が連続した数字で、その数字以外は同じ名前である一連の変数を指定する。 X1, X2, X3,・・・Xn → X1-Xn 【例】keep X1 - X10;
②名前範囲リスト
SASデータセット内の変数の位置をもとに、ある範囲の変数群を指定する。 ※SASデータセット内の変数の位置とは、変数が作成された順番と考えておけばよい。 変数Aから変数Xまで → A--X 【例】keep a -- x;
③名前の接頭語リスト
指定した文字列で始まるすべての変数を参照する。 【例】keep x: y:; この例では、xy, xz, yy, yzなど、「x」と「y」で始まる全ての変数をKEEPする。
④OFキーワードによるリスト形式
SAS関数の引数に上記の変数リストを指定する場合は、OFキーワードが必要となる。 【例①】sum(of x1 - x3 y1 - y3) 【例②】sum(of x1 - x3, of y1 - y3) 【例③】sum(of x1 - x3, y1 - y3)
例①と例②は同じ結果を返すが、例③はXとYの間にカンマ「,」が入っているので、Xはリストとして扱われるが、Yは単なる引き算となる。
つまり、リストとして扱われる範囲は、OFキーワードから、カンマ「,」まで、ということになる。