
目次
1. DATAステップ処理の流れ
通常、DATAステッププログラムは、入力データを読み込んで新しいSASデータセットを作成するという構造で記述される。入力データが外部ファイルであればINPUTステートメント、SASデータセットであればSETステートメントを使用することは、これまでに学んできた。
実は、DATAステップ内にINPUTやSETステートメントなどデータを読み込むためのステートメントが存在する場合、そのDATAステップは、読み込むデータの件数分、反復して処理がおこなわれる。具体的には下記の様な流れである。
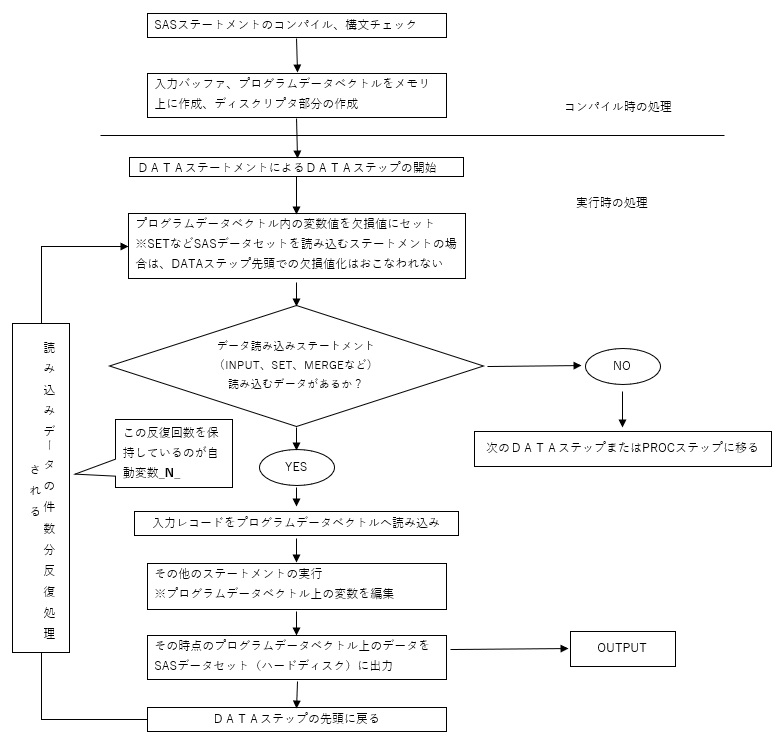
こうしたDATAステップ処理の流れを正確に把握するためには、プログラムデータベクトル(PDV)というSAS特有の仕組みを理解する必要がある。PDVとは、データセットへ出力するオブザべーションを作成するためにSASが使う一時的な変数の格納先のことである。PDVはメモリ上に構築される。
2. OUTPUTステートメント
DATAステップは、反復処理の度に、オブザべーションをSASデータセットへ自動出力してくれる。この自動出力のことを「暗黙のアウトプット」と呼ぶ。暗黙のアウトプットの実態は、データセットへオブザべーションを出力するためのOUTPUTステートメントが、自動的に実行されていることにほかならない。
OUTPUTステートメントは、DATAステップ内に明示することも可能である。その場合「暗黙のアウトプット」は無効化され、明示されたOUTPUTステートメントによってのみ、データセットへの出力が行われることになる。
これは、OUTPUTステートメントの明示によって任意なオブザべーションの出力制御が可能になるということであり、「ある条件に合致したオブザべーションだけ出力する」「同一オブザべーションを複数回出力する」といった処理をおこなうことが可能になる。実際の業務では、OUTPUTステートメントの活用は欠かすことができないテクニックである。
【例①】
以下のようなSASデータセット「list」があるとする。
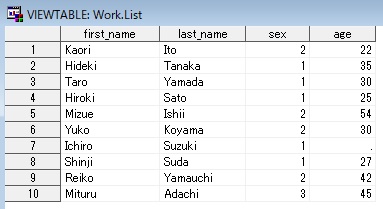
data mail femail; set list; if sex = 1 then output mail; else if sex = 2 then output femail; else put "WARNING:想定外の値が存在します。" (first_name last_name sex)(=); run;
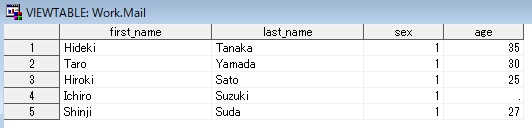
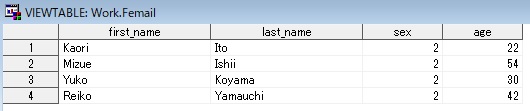
【実行結果】
実行すると、以下のSASデータセット「mail」と「femail」が作成される。
【ログ】
以下は、上記のプログラムを実行して出力されるログであり、このように想定していない変数値をWARNINGとして検出する方法も知っておくとよい。

【例②】
data output_sample; do i=1 to 2; do j=1 to 5; output; end; end; run;
【実行結果】
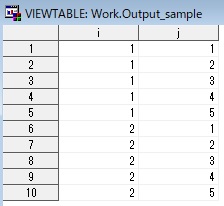
インデックス変数i、jが+1されるごとにアウトプットされている。
3. サブセット化IFステートメント
サブセット化IFステートメントは、条件に合致したオブザべーションの場合だけ、後続のステートメント処理を継続する働きをする。逆に、条件に合致しない場合、そのオブザべーションの処理は終了され、次のオブザべーションに処理が移ってしまう。こうした特徴から、ある条件に合致するオブザべーションだけに絞ったデータセットを作成するために、頻繁に利用するステートメントである。
なお、IF~THEN/ELSEステートメントとは、別のステートメントである。
IF 条件式;
【例】
以下のようなSASデータセット「list」があるとする。
age >= 30でサブセット化する。
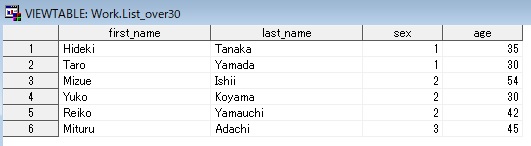
data list_over30; set list; if age >= 30; /*省略されているが、この位置に暗黙のOUTPUTステートメントが存在する*/ run;
【実行結果】
上記のプログラムを実行すると、サブセット化IFの条件に該当するレコードのみ、暗黙のOUTPUTステートメントが作用している。
4. DELETEステートメント
DELETEステートメントは、現在のオブザべーションの処理を中止し、次のオブザべーションに処理を移す働きをする。通常は、IF~THEN/ELSEステートメントと組み合わせて、ある条件に合致したオブザべーションをデータセットから除外する場合に使用する。
data list_under30; set list; if age >= 30 then delete; /*省略されているが、この位置に暗黙のOUTPUTステートメントが存在する*/ run;
【実行結果】
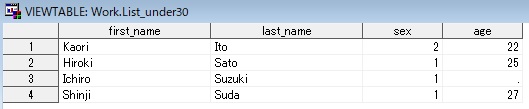
※欠損値「age=.」は、全ての数値の中で最小値として扱われるので、上記のプログラムでは出力される。
データセットのオブザべーションを絞る際の条件指定において、残すオブザべーションの条件を指定したいときはサブセット化IF、削除するオブザべーションの条件を指定したいときはDELETE、というのが基本的な使い分けとなる。
5. WHEREステートメント
条件に合致したオブザべーションだけを処理対象にする働きがある。サブセット化IFと似ているが、大きな違いは、データセットを読み込む段階で条件に合致するオブザべーションだけに絞ってしまう(該当するレコードだけをプログラムデータベクトルに取り込む)ことである。つまり、WHEREステートメントが指定されたDATAステップの場合、ステップ内のすべての処理が、絞られたレコードのみを対象におこなわれることになる。
サブセット化IFの場合、すべてのデータが必ずプログラムデータベクトル上に読み込まれ、DATAステップ内のサブセット化IFステートメントの実行段階で絞り込みがおこなわれる。(実行ステートメント)
上記の特徴があるので、WHEREステートメントはDATAステップ内のどの位置に記述しても、結果は同じになる。(非実行ステートメント)
一般に、大量のデータから条件に合致したデータを抽出する際には、WHEREの方がサブセット化IFよりも処理速度が速い。WHEREステートメントならではの特徴を理解したうえで、適宜利用したいステートメントである。
WHERE 条件式;
【例】
data list_where; set list; where sex = 1 and age >= 30; run;
WHEREステートメントで指定する変数はデータセットlistにあらかじめ存在していなければならない。DATAステップ内で新しく作成した変数をWHEREに指定することはできない。
【実行結果】
