

SUMMARYプロシジャとMEANSプロシジャの機能は被る部分が多いので、本記事では、SUMMARYプロシジャをメインに解説していきます。
ちなみに、私はSUMMARYプロシジャを使用する派です。
理由としては、デフォルトでアウトプット画面が非表示になっているからです。
出力が必要な時だけ、PRINTオプションを明示的に指定する方が、何となく好きなのです。
目次
構文
PROC SUMMARY DATA = 入力データセット NWAY /*出力統計量を_TYPE_の値が最大のオブザベーションに制限する*/ MISSING /*欠損値を有効な分類水準とみなす場合は指定する*/ PRINT /*結果をOUTPUT画面に出力する場合に指定する(MEANSプロシジャは不要)*/ ; WHERE 抽出条件; BY BYグループ変数; CLASS 分類変数; VAR 分析変数を指定する; WEIGHT WEIGHT用変数; ID 追加の変数を出力データセットに含める場合に指定する; TYPES 生成する分類変数の可能な組み合わせを指定する; WAYS 分類変数の一意の組み合わせを作成するための方法の数を指定する; OUTPUT OUT = 出力データセット /*統計量キーワード*/ N = SUM = ・・・ / AUTONAME /*複数の変数と統計量に対し一意の名前を生成する*/ ; RUN; 使用頻度の高いステートメントやオプションのみ記載 (といってもTYPESやWAYSはあんまり使わないかも・・・)
-

-
【SAS】SUMMARY・MEANSプロシジャで利用可能な統計量キーワード一覧
統計量キーワード一覧 種類 キーワード 統計量 備考 記述統計量 N 非欠損値数 MEAN 平均値 STDDEV または STD 標準偏差 MIN 最小値 MAX 最大値 NMISS 欠損値数 RAN ...
続きを見る

サンプルデータ
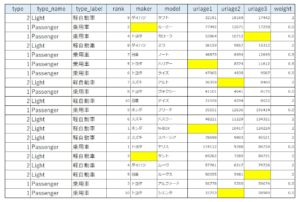
サンプルとして、以下のデータを使用していきます。
data sample;
infile datalines dlm="," dsd missover;
input
type :8.
type_name :$200.
type_label :$200.
rank :8.
maker :$200.
model :$200.
uriage1 :8.
uriage2 :8.
uriage3 :8.
weight :8.
;
datalines;
2,Light,軽自動車,9,ダイハツ,タフト,32191,18169,17442,2
1,Passenger,乗用車,2,,ルーミー,77492,12671,17258,0.5
1,Passenger,乗用車,4,トヨタ,カローラ,53864,10712,,0.5
2,Light,軽自動車,8,ダイハツ,ミラ,36159,9857,15312,2
1,Passenger,乗用車,7,日産,ノート,46879,8494,12649,0.5
1,Passenger,乗用車,5,トヨタ,ハリアー,,8374,11612,0.5
1,Passenger,乗用車,6,トヨタ,ライズ,47965,4838,9587,0.5
2,Light,軽自動車,7,スズキ,アルト,36359,,8460,2
1,Passenger,乗用車,8,トヨタ,ヴォクシー,41101,4641,8175,0.5
2,Light,軽自動車,10,日産,デイズ,31558,4294,8022,2
1,Passenger,乗用車,9,ホンダ,フリード,35551,12636,191414,0.5
2,Light,軽自動車,6,スズキ,ハスラー,48221,11229,134321,2
2,Light,軽自動車,1,ホンダ,N-BOX,,10417,124224,2
2,Light,軽自動車,2,スズキ,スペーシア,78698,9903,95521,2
1,Passenger,乗用車,1,トヨタ,ヤリス,119112,9788,84734,0.5
2,Light,軽自動車,3,,タント,69262,7289,84731,2
2,Light,軽自動車,4,ダイハツ,ムーヴ,57761,6317,79726,2
2,Light,軽自動車,5,日産,ルークス,50055,5981,,2
1,Passenger,乗用車,3,トヨタ,アルファード,56778,5359,59674,0.5
1,Passenger,乗用車,10,トヨタ,シエンタ,33753,,58989,0.5
;
run;
黄色セルは欠損値を表しています。
使い方
※SAS Studioで実行しているため、BaseSASと出力結果が異なる場合がございます。
CLASS・VAR・OUTPUTステートメント
SUMMARY・MEANSプロシジャでは、CLASS・VAR・OUTPUTステートメントの3つを使用して集計することが基本になります。
以下は、簡単な集計例です。
proc summary data = sample;
class type maker;
var uriage1 - uriage3;
output
out = sample_summary
n(uriage1) = uriage1
sum(uriage2 - uriage3) = uriage2 - uriage3
;
run;
以下は出力データセットsample_summaryの中身です。
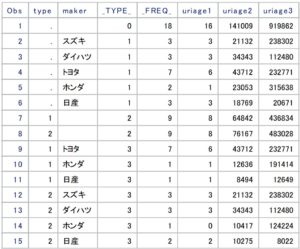
変数_TYPE_と_FREQ_は自動で生成されます。
変数_TYPE_の変数値が小さい順に0、1、2、3の4つとなっていますが、これは分類変数の可能な組み合わせ数を表しており、2の(CLASSステートメントに指定した変数の数)乗の組み合わせになります。
分類変数の数が3つなら2の3乗=8(_TYPE_=0~7)、4つなら2の4乗の16(_TYPE_=0~15)になります。
OUTPUTステートメントでは、非欠損値数を算出するNと、合計を算出するSUMを統計量キーワードとして指定しています。
「n(uriage1) = uriage1」の左辺のカッコ内のuriage1は、VARステートメントで指定したuriage1を指しており、右辺のuriage1は算出後の統計量を格納する変数名を表しています。
つまり、「n(uriage1) = uriage1_n」と修正すれば、出力データセット内の変数はuriage1からuriage1_nに変わります。
NWAYオプション
このNWAYオプションの使用頻度は極めて高く、業務では必須になると思います。
むしろ、NWAYを使用しないならSUMMAY・MEANSプロシジャは使用するべきではない、と個人的には考えております。
というのも、NWAYを指定しないと、出力データセットに含まれる分類変数の組み合わせ数が多くなるため、TYPESステートメントや自動で生成される変数_TYPE_でのコントロールが必要になるからです。
これが、プログラムの長期運用や、他の人が引き継ぐことを想定すると厄介なのです。
細かく説明すると長くなるのでざっくり言いますが、おそらく、プログラムが散らかって、可読性が低下し、ミスの発生率が上がる、と思います。
前置きが長くなりましたが、以下がNWAYを指定した集計例です。
proc summary data = sample
nway;
class type maker;
var uriage1 - uriage3;
output
out = sample_summary_nway
n(uriage1) = uriage1
sum(uriage2 - uriage3) = uriage2 - uriage3
;
run;
以下は出力データセットsample_summary_nwayの中身です。
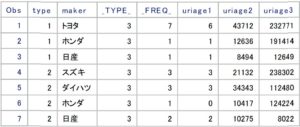
上図の集計データは、最初に出力したsample_summaryの赤枠部分になります。
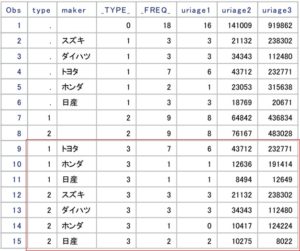
これは、変数_TYPE_が最大になるレコードのみ、を出力したものです。
業務で必要となるのは、ほとんどの場合がこの赤枠部分のみです。
MISSINGオプション
CLASSステートメントに指定した分類変数に欠損値が含まれている場合、通常であれば、その分類の組み合わせは出力されません。
しかし、MISSINGオプションを指定すれば、欠損値を有効な分類水準とみなすことができ、出力されます。
proc summary data = sample
nway
missing;
class type maker;
var uriage1 - uriage3;
output
out = sample_summary_missing
n(uriage1) = uriage1
sum(uriage2 - uriage3) = uriage2 - uriage3
;
run;
MISSINGオプションを指定したことで、以下のように、変数makerが欠損値の組み合わせも出力されるようになりました。
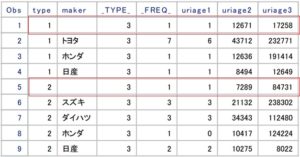
基本的にMISSINGオプションは指定した方が良いです。
理由としては、分類変数に意図しない欠損値が含まれていた場合、その存在に気付くことができるからです。
AUTONAMEオプション
VARステートメントに指定したすべての分析変数に対し、指定した統計量キーワードの種類分の統計量を算出したいときに使えるのがAUTONAMEオプションです。
AUTONAMEを指定すれば、分析変数の接尾に統計量キーワードが自動で付くため、出力変数名がユニークになります。
まずは、AUTONAMEオプションなしの集計例です。
/*AUTONAMEなし*/
proc summary data = sample
nway
missing;
class type maker;
var uriage1 - uriage3;
output
out = sample_summary_not_autoname
n(uriage1 - uriage3) = uriage1_n uriage2_n uriage3_n
sum(uriage1 - uriage3) = uriage1_sum uriage2_sum uriage3_sum
;
run;
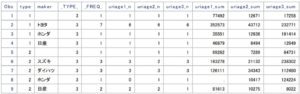
続いて、AUTONAMEありの集計例です。
/*AUTONAMEあり*/
proc summary data = sample
nway
missing;
class type maker;
var uriage1 - uriage3;
output
out = sample_summary_autoname
n =
sum =
/ autoname
;
run;
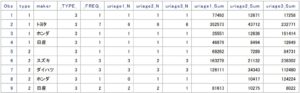
AUTONAMEありとなしの出力の違いは、上記の例で言えば、出力変数の接尾に付くキーワードの頭文字が「Num」や「Sum」のように大文字になることだけです。
ただし、使用上の注意点として、キーワードが付与されたあとの変数名が、変数の命名規則である最大32文字を超えないようにする必要があります。
IDステートメント
SUMMARY・MEANSプロシジャでは、入力データセット内の変数のうち出力データセットに含まれるのは、BYやCLASS、OUTPUTステートメントで指定した変数のみになります。
グループ変数や分類変数じゃないけど一緒に出力したいなぁ、というときに使えるのがIDステートメントです。
以下はその使用例です。
proc summary data = sample
nway
missing;
class type maker;
id type_name type_label;
var uriage1 - uriage3;
output
out = sample_summary_id
n(uriage1) = uriage1
sum(uriage2 - uriage3) = uriage2 - uriage3
;
run;
以下のように、IDステートメントで指定したtype_nameとtype_labelが追加されています。
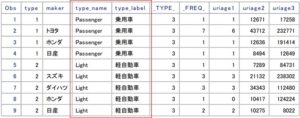
使用頻度としては、ときどき使用する、という感じです。
要約統計量
出力データセットはいらなくて、サクッと要約統計量だけ見たい、という方はOUTPUTステートメントの記述は不要で、PRINTオプションを指定してください。
ちなみに、MEANSプロシジャはデフォルトでPRINT状態になっているので、わざわざ指定する必要はございません。
以下はその例です。
proc summary data = sample
missing
print;
class type maker;
var uriage1 - uriage3;
run;
上記を実行すると以下のアウトプット画面が表示されます。
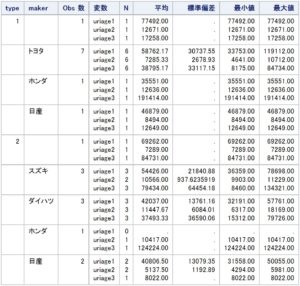
デフォルトでは、N、平均、標準偏差、最小値、最大値が出力されますが、以下のように、必要な統計量キーワードのみを指定することもできます。
proc summary data = sample
missing
print
nmiss var uclm lclm;
class type maker;
var uriage1 - uriage3;
run;
上記を実行すると以下が表示されます。
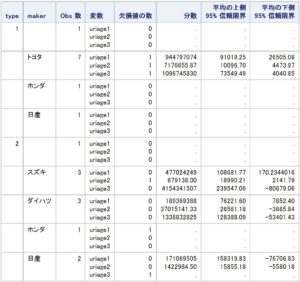
-
-
【SAS】SUMMARY・MEANSプロシジャで利用可能な統計量キーワード一覧
統計量キーワード一覧 種類 キーワード 統計量 備考 記述統計量 N 非欠損値数 MEAN 平均値 STDDEV または STD 標準偏差 MIN 最小値 MAX 最大値 NMISS 欠損値数 RAN ...
続きを見る